eISSN: 2093-8462 http://jesk.or.kr
Open Access, Peer-reviewed
eISSN: 2093-8462 http://jesk.or.kr
Open Access, Peer-reviewed
Sung-Hee Kim
10.5143/JESK.2018.37.1.63 Epub 2018 March 01
Abstract
Objective: The aim of this study is to investigate whether visual aids can enhance decision outcomes for multi-attribute choice making problems with practical datasets.
Background: Information visualization techniques have been used to develop visual aids to help consumers process the given information, thus improving decision outcomes by increasing decision quality. However, due to the fact that decision quality is difficult to measure, several studies used context-free data to minimize the impact of participants' preference structures to reduce subjective factors. To better understand whether these visual aids are effective in a more practical setting, we need to conduct studies using data with context.
Method: The experiment was conducted as a between-subject study with two interfaces, SimulSort for the interactive visualization interface and Typical Sorting for the non-visual traditional interface. Each participant had three decision making trials and the decision-making quality was measured by selecting the nondominated option that is considered as the best choice. A total of 127 participants participated through an online experiment platform.
Results: Using the SimulSort interface, the odds of selecting a nondominated option, compared to not selecting it, increased and has a significant effect. Both the interface and type of selected option had significant main effects on the time spent. A post-hoc analysis revealed that the type of selected option had significant effect for the participants who used SimulSort by spending more time to make a decision, however, this effect was not present for the participants who used Typical Sorting. The participants were generally confident on their decisions while using both interfaces.
Conclusion: The results revealed that SimulSort could enhance the probability of making a better decision than compared to Typical Sorting. The study also shows an effective way to conduct a controlled study that has an objective measure for decision making using data with context.
Application: The results of the experiment can help implement visual aids to help consumers make better decisions in everyday life.
Keywords
Decision making Information visualization Visual aid Interface
Individuals experience multi-attribute decision making in their everyday lives such as when they purchase a product, select a college, or decide on a house to rent. Multi-attribute decision making occurs when a consumer has several alternatives and attributes associated with a choice. When choosing a car to purchase, for example, one can consider price, engine, horsepower, fuel efficiency, and several other factors (Yoon and Hwang, 1995). With the advent of computing and information technology, consumers are now facing vast amounts of information for their choice making. Several studies also have shown that decision makers often experience information overload and become overwhelmed (Chen et al., 2009; Grant and Schwartz, 2011; Hahn et al., 1992).
In order to help decision makers, researchers have been applying information visualization techniques and have demonstrated that these techniques could improve decision performance (Carenini and Loyd, 2004; Williamson and Shneiderman, 1992). These visualizations enable people to explore large quantities of information and gain insights from them. Since multi-attribute decision making involves effortful cognitive processes, various forms of visual interfaces can help decision makers achieve higher decision quality and satisfaction (Bautista and Carenini, 2008; Savikhin et al., 2008). However, to show that the visualization was effective, researchers conducted controlled studies to context-free data to better understand the information-processing perspective or just measure subjective ratings such as satisfaction level. We need to investigate the impact of visualization techniques in a rather practical setting.
In this study, we use a visual aid "SimulSort" that is a tabular information visualization to help multi-attribute decision making. The practical data sets with context were about selecting the best apartments, laptops, and printers. We conducted an online study to show that visual aids help people to make a better decision.
2.1 Visual aids for multi-attribute decision making
To alleviate high cognitive activities that occurs during multi-attribute decision making, various information visualization techniques have been utilized by presenting insights more interpretable and by lowering the cognitive load for decision makers (Wittenburg et al., 2001). A parallel-coordinates is one of the common ways to project a large amount of multi-dimensional data on a 2-D display to analyze multi-attribute data (Wang et al., 2003). It provides an overview of the data, however, additional interaction is needed to read the raw data. TableLens is an example of a visual interaction tool with tabular form (Rao and Card, 1994). It expands the boundaries of a table that can be shown on a screen by presenting a large table in a symbolic style and allowing users to expand certain areas for detailed examination. Parallel bargrams is an example that exceeds a generic tabular form and sorts all the attributes in parallel rows at the same time (Wittenburg et al., 2001). It is designed to help consumers with multi-attribute mechanized purchasing decisions by providing simultaneously comparable attribute values for different alternatives. FOCUS (Spenke et al., 1996), EZChooser (Wittenburg et al., 2001), and InfoZoom (Spenke and Beilken, 2000) are some visualization tools that apply the idea of parallel bargrams. However, as these visual aids have several features implemented, the evaluation on the tools were mostly measuring the overall satisfaction level during a task, rather than on the decision-making performance.
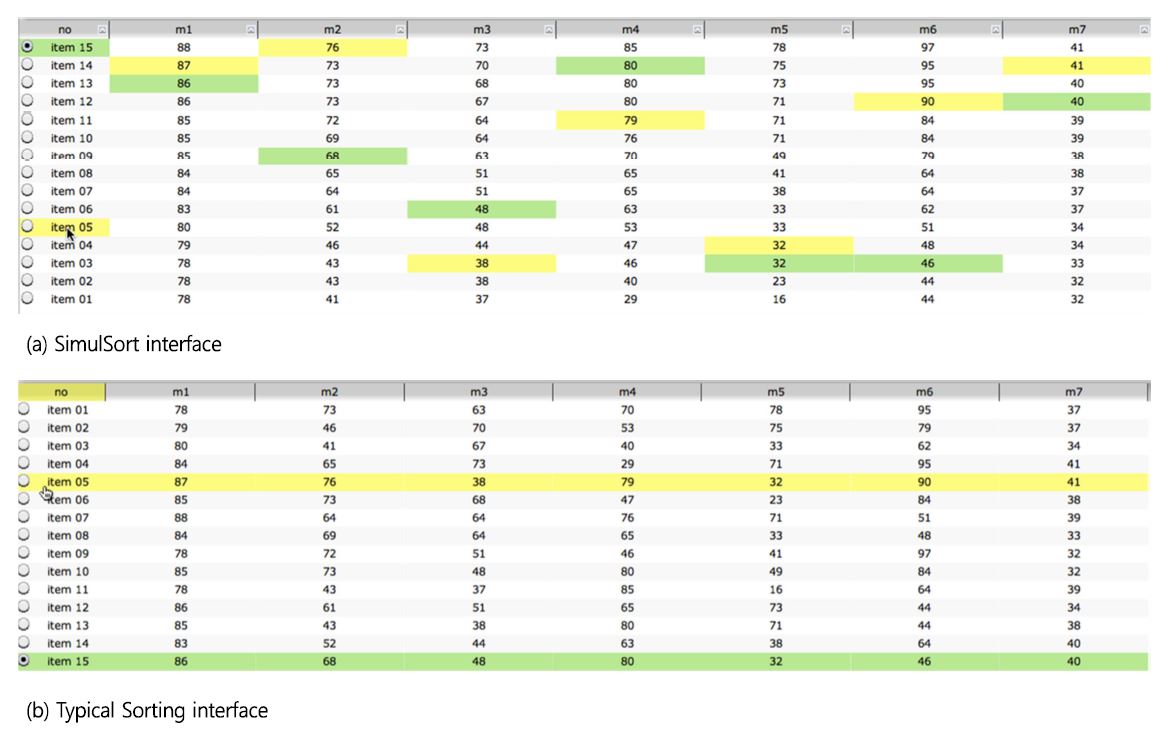
SimulSort (SS) is another visualization technique that also aims to help with daily multi-attribute decision making (Hur and Yi, 2009). Compared to the visualizations explained above, the visual factor of the tool is more simple and it has a clear counterpart interface, Typical Sorting explained below, that provides an opportunity to conduct a controlled study. As shown in Figure 1(a), SS presents all columns sorted simultaneously so that one can see the relative values or utilities (i.e., pros and cons) of an alternative over multiple attributes. This visual representation is expected to avoid the constant shuffling of rows induced by sorting a column in the Typical Sorting (TS) interface (i.e., Figure 1(b)) and to offer insights to users by presenting the trend of the data at a glance. Typical Sorting can be considered as a traditional spreadsheet.
2.2 Experiments using data with context
The main difficulty for conducting an experiment for decision making is that people have different preference structure, therefore it is hard to define what the best decision is. For example, when purchasing a car, some consumers might consider price as the most important factor, while others consider horsepower. Therefore, if we give a decision-making task with contextual data, the best option will be different for each participant. To overcome this difficulty, several studies were conducted with context-free data as they can guarantee what the best option has with calculating the utility in a mathematical way. For example, context-free data has attributes that are labeled with meaningless names such as 'm1' and 'm2' as shown in Figure 1(a). Therefore, people do not have any preference on the attributes and the attributes are considered to be equally important. Although context-free data helps to conduct a controlled experiment, the experiment setting is considered to be artificial.
For a more realistic experimental setting, contextual data should be used that has options with attributes and values considered from real life as shown in Table 1. One way to control different preference structure but use this kind of contextual data, Lurie (2004) suggested to inject the preference structure by giving explicit weights to attributes. For example, if there are attributes such as price, weight, distance to store, the experiment instruction explains that the weight of each attribute is 0.6, 0.2, and 0.2. However, it is hard to know whether the participants actually considered the different weight values. Lastly, Haubl and Trifts (2000) conducted an experiment by designing the dataset to have dominant and nondominant options. An option is dominated if at least one alternative is superior in at least one attribute while not being inferior in any other attribute. In contrast, a nondominated alternative is the case where no alternative is superior to another attribute without being inferior to at least one other attribute. If one selected a dominated option, it means that there is at least one option that is dominating the selected option, which makes the selection a poor choice. In other words, if a decision maker selects a nondominated option, it can be interpreted as a good decision because it dominates the other remaining options. The advantage of this measure is that it is immune to the weights of different attributes. Although a person weighs a certain attribute over another, the better decision is to select one of the nondominated options. Therefore, even with contextual data, the best choice is the same for everyone.
3.1 Dataset design
The author designed the three practical data sets with context (i.e., apartments, laptops, and printers), following the method by Haubl and Trifts (2000). Commonly, each data set had 30 alternatives for three brands with seven attributes. There are 10 alternatives for each brand and there is one nondominated alternative among the 10 alternatives. Thus, there are a total of three nondominated alternatives for the three brands. In the following description, the author explained the design method of the data sets based on an exemplar of the apartment data set.
Table 1 shows the attributes, how the value is preferred to be a better option (i.e., high or low), the number of levels for each attribute, and the values for each level. For each attribute, whether higher or lower value is preferred followed common sense as most people prefer a cheaper price to a higher price. The possible values in Table 1 for each attribute are sorted following the preference structure.
|
Attributes |
Rent |
Square |
Maintenance (best: 10) |
Cleanness (best: 10) |
Office ataff (best: 10) |
Distance (minutes) |
Recommended |
|
Preferred value |
Low |
High |
High |
High |
High |
Low |
High |
|
# of levels |
6 |
6 |
3 |
3 |
3 |
6 |
3 |
|
Values |
1,765 |
945 |
8 |
9 |
9 |
10 |
94 |
|
1,770 |
930 |
7 |
7 |
8 |
12 |
92 |
|
|
1,785 |
925 |
6 |
6 |
7 |
15 |
88 |
|
|
1,815 |
915 |
- |
- |
- |
17 |
- |
|
|
1,865 |
910 |
- |
- |
- |
18 |
- |
|
|
1,890 |
905 |
- |
- |
- |
20 |
- |
Table 2 shows the data set of apartment, which was used in this study. The data set has a total of 30 alternatives for three brands, each brand has 10 alternatives, and each alternative has seven attributes. Out of the 30 alternatives, three are mutually nondominated and one of each nondominated alternative is assigned to a certain brand (i.e., management in Table 2). Having one nondominated option for each brand guarantee that regardless of brand preference, there is a single most preferred alternative within that brand. Among the seven attributes, three have six levels each (i.e., rent, square feet, and distance as shown in Table 1) while the remaining four attributes have three levels each (i.e., maintenance, cleanness, office staff, and recommended rating as shown in Table 1). The three nondominated alternatives used the following rule: For the first three attributes with six levels, all three nondominated alternatives were assigned with the best level represented as one, the second best represented as other, and the third best as the remaining attribute. Because there are six combinations of value assignments, the author had selected three combinations for the nondominated options. For the other four attributes, the best level of the three-level values was assigned. At the end of Table 2, the error size column is the count of attributes that are dominated by the nondominated option. For the experiment, the order of the alternatives was randomized. To better understand the rationale of this dataset, if a decision maker selects Apt02, he or she is making a bad decision because Apt01 offers more square feet while its other attribute values remain the same.
|
Option |
Management |
Rent |
Square feet |
Maintenance |
Cleanness |
Office |
Distance |
Recommended |
Error size |
|
Apt01* |
Lakeview |
1,770 |
945 |
8 |
9 |
9 |
15 |
94 |
0 |
|
Apt02 |
Lakeview |
1,770 |
930 |
8 |
9 |
9 |
15 |
94 |
1 |
|
Apt03 |
Lakeview |
1,785 |
945 |
8 |
9 |
9 |
15 |
92 |
2 |
|
Apt04 |
Lakeview |
1,785 |
945 |
8 |
7 |
9 |
17 |
94 |
3 |
|
Apt05 |
Lakeview |
1,770 |
945 |
6 |
7 |
8 |
18 |
94 |
3 |
|
Apt06 |
Lakeview |
1,890 |
925 |
8 |
9 |
8 |
15 |
88 |
4 |
|
Apt07 |
Lakeview |
1,770 |
945 |
6 |
7 |
9 |
20 |
92 |
4 |
|
Apt08 |
Lakeview |
1,865 |
945 |
7 |
7 |
8 |
18 |
88 |
5 |
|
Apt09 |
Lakeview |
1,785 |
945 |
8 |
6 |
7 |
18 |
92 |
5 |
|
Apt10 |
Lakeview |
1,815 |
930 |
6 |
7 |
8 |
20 |
94 |
6 |
|
Apt11* |
Foursquare |
1,785 |
930 |
8 |
9 |
9 |
10 |
94 |
0 |
|
Apt12 |
Foursquare |
1,815 |
930 |
8 |
9 |
9 |
10 |
94 |
1 |
|
Apt13 |
Foursquare |
1,785 |
925 |
8 |
9 |
9 |
10 |
94 |
2 |
|
Apt14 |
Foursquare |
1,785 |
930 |
8 |
7 |
9 |
12 |
92 |
3 |
|
Apt15 |
Foursquare |
1,890 |
930 |
7 |
9 |
8 |
10 |
94 |
3 |
|
Apt16 |
Foursquare |
1,785 |
905 |
8 |
7 |
9 |
12 |
88 |
4 |
|
Apt17 |
Foursquare |
1,890 |
905 |
8 |
9 |
7 |
15 |
94 |
4 |
|
Apt18 |
Foursquare |
1,815 |
915 |
6 |
9 |
8 |
10 |
92 |
5 |
|
Apt19 |
Foursquare |
1,865 |
910 |
7 |
6 |
8 |
10 |
92 |
5 |
|
Apt20 |
Foursquare |
1,785 |
925 |
7 |
6 |
7 |
12 |
88 |
6 |
|
Apt21* |
Paradigm |
1,765 |
925 |
8 |
9 |
9 |
12 |
94 |
0 |
|
Apt22 |
Paradigm |
1,765 |
925 |
8 |
9 |
9 |
10 |
94 |
1 |
|
Apt23 |
Paradigm |
1,765 |
905 |
8 |
9 |
9 |
12 |
94 |
2 |
|
Apt24 |
Paradigm |
1,765 |
910 |
8 |
9 |
9 |
15 |
92 |
3 |
|
Apt25 |
Paradigm |
1,770 |
925 |
7 |
9 |
7 |
17 |
94 |
3 |
|
Apt26 |
Paradigm |
1,765 |
915 |
8 |
6 |
9 |
18 |
88 |
4 |
|
Apt27 |
Paradigm |
1,765 |
910 |
6 |
6 |
9 |
20 |
94 |
4 |
|
Apt28 |
Paradigm |
1,770 |
915 |
7 |
9 |
7 |
17 |
92 |
5 |
|
Apt29 |
Paradigm |
1,765 |
905 |
6 |
7 |
8 |
18 |
88 |
5 |
|
Apt30 |
Paradigm |
1,765 |
915 |
7 |
7 |
8 |
20 |
88 |
6 |
3.2 Participants
A total of 220 crowdsourced workers were recruited. However, 93 participants were removed if they had different preference structure of what we assumed as in Table 1. Because this common sense might not be guaranteed and people may have different preferences for these values, the author collected their preference structure afterwards and removed the collected data if they were different from this assumption. Eventually, 127 legitimate participants (53 female) remained with 67 participants for SS and 60 participants for TS. The ages ranged from 19 to 64 years old (m = 33.0, s = 10.3).
3.3 Experiment design and procedure
We conducted the experiment through Amazon Mechanical Turk, a well-known crowdsourcing platform. The crowdsourcing approach has several advantages over conventional, controlled laboratory studies (Kittur et al., 2008), including recruiting a large number of participants with diverse backgrounds in a more natural environment.
The experiment was conducted as a between-subject study with two interfaces (SS vs. TS). Each participant had 10 practice trials with context-free data to learn how to use the interface 1. After the 10 practice trials, the participants had three trials with different data sets: apartment, laptop, and printer. For each trial, a scenario was given. The following scenario is for the apartment data set: "In this trial you are making a decision for yourself. Imagine that you have moved to a new city and you are finding an apartment with one bedroom. Attributes you can consider are Management, Rent ($), Square Feet, Maintenance Rating (Best: 10), Cleanness Rating (Best: 10), and Office Staff Service Rating (Best: 10), Distance to work place or school (minutes), and Recommended by others (%)".
3.4 Measurements
To determine the objective measurement of decision quality, I recorded whether final selection was the dominated or nondominated option. For the subjective measurement, the confidence level of the final decision was asked with a 7-point likert scale (7-point Likert scale question: from strongly disagree to strongly agree). The statement to evaluate confidence level was "I am confident of my decision by selecting the best option". The time spent making a decision for each trial was also recorded.
3.5 Reward design
The base payment for participating in the task was $1.80, which was rewarded if they participated. The maximum bonus was calculated based on their performance for each trial in which they could earn a maximum of $0.10. The payment for the 10 practice trials was proportional to participants' decision quality (Hur and Yi, 2009) and for the trials showing data with context, participants were paid $0.10 regardless of their selection. The trials showing data with context was meant to be realistic of making a decision for themselves, therefore, the author did not penalize for selecting a dominated option. If they were penalized by selecting a dominated option, it may have changed their behavior of making a choice. The average earning for the participants was $2.90 (s = 0.15).
4.1 Decision quality
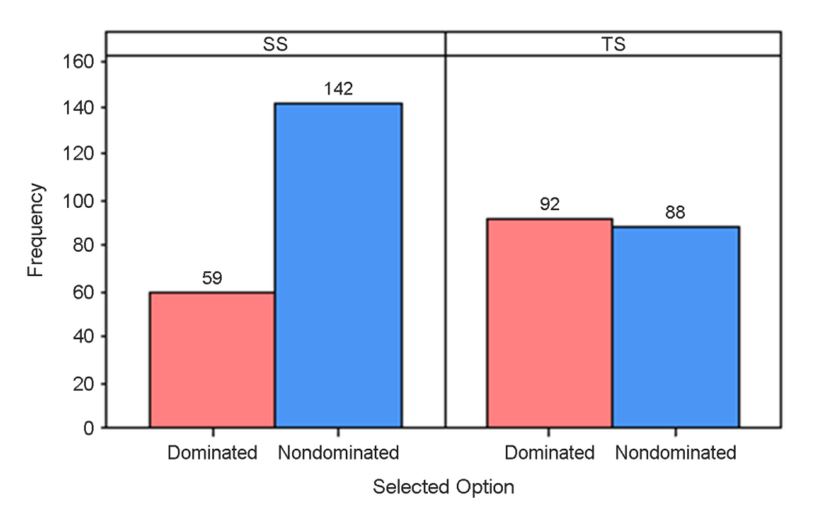
The logistic regression model was used with PROC LOGISTIC in SAS. If one of the nondominated options was selected, it was graded as 1, and if not, it was graded as 0. This model was meant to predict the probability of selecting the nondominant option while using each interface. As shown in Figure 2, the interface showed that it has significant impact on improving the model fit (Wald Chi-Square = 18.4141, p < 0.0001). Using the SS interface, the odds of selecting a nondominated option, compared to not selecting it, increased by a factor of 2.516 (95% CI: 1.651, 3.834).
4.2 Time spent
A repeated measures ANOVA test was employed using the PROC MIXED procedure in SAS. The interface (F(1,125) = 11.35, p < 0.001) had a significant main effect with the mean time spent for SS and TS as 137.4 seconds and 87.24 seconds, respectively.
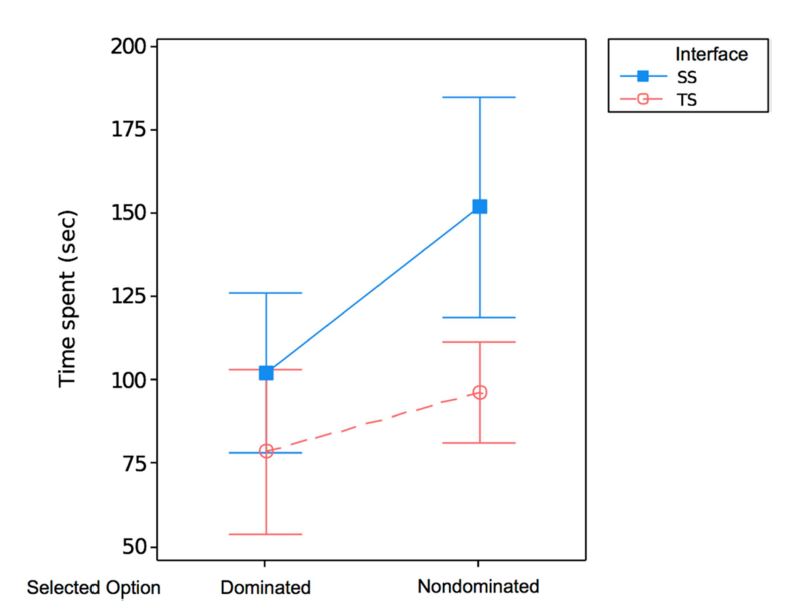
To better understand this phenomenon, the author added the type of selected option, whether it was dominated to nondomiated option, to the model for analysis. The same repeated measures ANOVA test was employed as above. Both the interface (F(1,125) = 6.55, p = 0.0117) and type of selected option (F(1,77) = 0.033, p < 0.001) had significant main effects on the time spent. A post-hoc analysis for comparison with Bonferroni adjustment revealed that the type of selected option had significant effect for the participants who used SS (F(1,77) = 4.92, p = 0.0295) with the mean time spent for nondominated option and dominated option as 151.96 and 102.34 seconds, respectively. However, this effect was not present for the participants who used TS (F(1,77) = 0.68, p = 0.4111) with the mean time spent for nondominated option and dominated option as 96.33 and 78.53 seconds, respectively. A post-hoc analysis also revealed that with the case of not selecting a nondominated option, there was no significant difference between the two interfaces (F(1,77) = 0.98, p = 0.3260) with the mean time spent for SS and TS as 102.34 seconds and 78.53 seconds, respectively. However, in the case of selecting a nondominated option, there was a significant effect of the interface (F(1,77) = 8.06, p = 0.0058) with the mean time spent for SS and TS as 151.96 seconds and 96.33 seconds, respectively.
4.3 Confidence
The Kruskal-Wallis non-parametric test revealed that the type of interface had a significant impact on the perceived self-explanatory level (χ2 (1) = 8.0173, p = 0.0046). The mean rating was 5.82 for SS and 5.50 for TS, while 5 stands for 'Somewhat Agree' and 6 stands for 'Agree'. Therefore, although there is statistically significant difference, the participants were generally confident on their decisions with both SS and TS.
The purpose of this study was to examine whether SS could help the decision-making process showing data with context. The study of Hur et al. (2013) revealed that the decision quality was higher spending shorter time in SS compared to TS with context-free data. In this experiment with contextual data, the results of making a choice for an apartment, printer, and laptop, showed that SS compared to TS, led to an increased share of the cases that selected a nondominated option that was considered to be a good decision. On the other hand, the results for time spent making a decision had opposite results. With the data with context, participants spent a longer time with SS compared to TS. As shown in Figure 3, the longer time spent originates in cases particularly when participants selected the nondominated options.
People are known to make a cost-benefit tradeoff while establishing decision-making strategies (Payne et al., 1993; Shah and Oppenheimer, 2008). This means that although the decision makers can reach a better decision by applying more effort, if the effort to apply the search strategy exceeds their capacity, they tend to stop at the suboptimal choice. In this experiment, longer time spent may be interpreted as SS requiring more effort, however, the author believes that cost of additional effort with SS-in this case spending more time-might have been perceived worthwhile because participants could then expect the outcome to be good without making a trade-off between the two.
As a result of this experiment, the author could observe one optimal way of using SimulSort: to detect dominated options. Regardless of preference, selecting a dominated option is a poor decision. In a particular case, while comparing two options, SimulSort can help the user to easily find the bad option. This was also shown in the comments that one of the participants revealed for explaining the strategy they used: "I'd start by highlighting 1, making a series of binary judgments as I worked my way down. Many could be passed quickly [by] looking at the sweep of color; some I had to compare more closely by looking at relative positioning in the individual column". Another way to apply this strategy is to create a smaller set of options. The smaller set of options is often called considerations set (Hauser and Wernerfelt, 1990; Lapersonne et al., 1995). If one could easily rule out the bad choices, the remaining set of possibilities would become smaller, consisting of better options. However, further experiments should be conducted to understand different strategies while using these kinds of visual aids.
The use of context-free data in these previous studies had the advantage of understanding the information processing behavior by minimizing individual differences induced by the context. However, it is still important to know if SimulSort is beneficial in a rather realistic context. The effectiveness of decision quality while using visual aids was in line with studies that had context-free data. The results revealed that SimulSort could enhance the probability of making a better decision than compared to Typical Sorting. However, the time measurements had different results, which shows that considering the context of data has impact and it could change the decision-making behavior of the participants compared to context-free data. Moreover, the method of using dominated/nondominated options could provide a obejective measure for decision quality while not being biased by the individual's preference structure.
The author attempted to understand the impact with a realistic decision making context. However, there are several other ways to extend the study in terms of dataset size and context, different ways of measuring the decision outcome, as well as different visual interfaces. These techniques should be surveyed more comprehensively and examined for their effectiveness. If we can investigate thoroughly to deepen our understanding of "visualized decision making", this can lead to building guidelines for developing effective visual aids that will help consumers.
References
1. Bautista, J. and Carenini, G., An empirical evaluation of interactive visualizations for preferential choice, Proceedings of the Working Conference on Advanced Visual Interfaces (pp. 207-214). Napoli, Italy, 2008.
Crossref
2. Carenini, G. and Loyd, J., ValueCharts: analyzing linear models expressing preferences and evaluations, Proceedings of the Working Conference on Advanced Visual Interfaces (pp. 150-157). Gallipoli, Italy, 2004.
Crossref
Google Scholar
3. Chen, Y.C., Shang, R.A. and Kao, C.Y., The effects of information overload on consumers' subjective state towards buying decision in the internet shopping environment, Electronic Commerce Research and Applications, 8(1), 48-58, 2009.
Crossref
Google Scholar
4. Grant, A.M. and Schwartz, B., Too much of a good thing the challenge and opportunity of the inverted utility, Perspectives on Psychological Science, 6(1), 61-76, 2011.
Crossref
Google Scholar
5. Hahn, M., Lawson, R. and Lee, Y.G., The effects of time pressure and information load on decision quality, Psychology and Marketing, 9(5), 365-378, 1992.
Crossref
Google Scholar
6. Haubl, G. and Trifts, V., Consumer decision making in online shopping environments: The effects of interactive decision aids, Marketing Science, 19(1), 4-21, 2000.
Crossref
Google Scholar
7. Hauser, J.R. and Wernerfelt, B., An evaluation cost model of consideration sets. Journal of Consumer Research, 393-408, 1990.
Crossref
Google Scholar
8. Hur, I. and Yi, J.S., SimulSort: multivariate data exploration through an enhanced sorting technique, Human-Computer Interaction: Novel Interaction Methods and Techniques, 5611, 684-693, 2009.
Crossref
Google Scholar
9. Hur, I., Kim, S.H., Samak, A. and Yi, J.S., A comparative study of three sorting techniques in performing cognitive tasks on a tabular representation, International Journal of Human-Computer Interaction, 29(6), 379-390, 2013.
Crossref
Google Scholar
10. Kittur, A., Chi, E.H. and Suh, B., Crowdsourcing user studies with mechanical turk, Proceeding of the Twenty-Sixth Annual SIGCHI Conference on Human Factors in Computing Systems (pp. 453-456). Florence, Italy, 2008.
Crossref
Google Scholar
11. Lapersonne, E., Laurent, G. and Le Goff, J.J., Consideration sets of size one: An empirical investigation of automobile purchases. International Journal of Research in Marketing, 12(1), 55-66, 1995.
Crossref
Google Scholar
12. Lurie, N.H., Decision making in Information Rich environments: The role of information structure, Journal of Consumer Research, 30(4), 473-486, 2004.
Crossref
Google Scholar
13. Payne, J.W., Bettman, J.R. and Johnson, E.J., The adaptive decision maker. Cambridge University Press, 1993.
Crossref
Google Scholar
14. Rao, R. and Card, S.K., The table lens: Merging graphical and symbolic representations in an interactive focus+ context visualization for tabular information. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems Systems: Celebrating Interdependence (pp. 318-322), 1994.
Crossref
Google Scholar
15. Savikhin, A., Maciejewski, R. and Ebert, D., Applied visual analytics for economic decision-making, IEEE Symposium on Visual Analytics Science and Technology (pp. 107-114), 2008.
Crossref
Google Scholar
16. Shah, A. and Oppenheimer, D., Heuristics made easy: An effort-reduction framework. Psychological Bulletin, 134(2), 207-222, 2008.
Crossref
Google Scholar
17. Spenke, M. and Beilken, C., InfoZoom - analysing formula one racing results with an interactive data mining and visualisation tool. Ebecken, N. Data mining II (pp. 455-464), 2000.
Crossref
Google Scholar
18. Spenke, M., Beilken, C. and Berlage, T., FOCUS: the interactive table for product comparison and selection. In Proceedings of the 9th annual ACM symposium on user interface software and technology (pp. 41-50). New York, USA, 1996.
Crossref
Google Scholar
19. Wang, J., Peng, W., Ward, M.O. and Rundensteiner, E.A., Interactive hierarchical dimension ordering, spacing and filtering for exploration of high dimensional datasets. IEEE Symposium on Information Visualization 2003 (pp. 105-112), 2003.
Crossref
Google Scholar
20. Williamson, C. and Shneiderman, B., The dynamic HomeFinder: evaluating dynamic queries in a real-estate information exploration system, Proceedings of the 15th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 338-346), 1992.
Crossref
Google Scholar
21. Wittenburg, K., Lanning, T., Heinrichs, M. and Stanton, M., Parallel bargrams for consumer-based information exploration and choice, Proceedings of the 14th annual ACM symposium on user interface software and technology (pp. 51-60). New York, NY, USA, 2001.
Crossref
Google Scholar
22. Yoon, K. and Hwang, C., Multiple attribute decision making: An introduction. SAGE, 1995.
Crossref
Google Scholar
PIDS App ServiceClick here!